Introduction
Many normal developers simply think that hash tables are something to store a key-value pair. That’s it. What are its applications are not known. Some people directly correlate with C++ STL data structures map and hash map. :)
hash map is faster than map. But why is that?
We have seen many sorting algorithms already. For searching there are neat data structures available which does our job. What is necessary for a best searching algorithm?
- lookup should be O(1)
- insert should also be O(1)
- delete should also be O(1)
In the sorting case, this is never possible. :) But sorting becomes the basis for searching like binary search. But even that won’t give you O(1).
That’s where we go for the dictionaries. Dictionaries or Hash tables, both mean the same. Don’t confuse!!.. I did that.. :)
Dictionaries are nothing but hash tables which gives you lookup of O(1). Just an another name. :D
Concept
To explain this simply, take a normal English dictionary. You know the word you need to search for. Just take the dictionary and go directly to the first letter page then continue to scan for the second letter. This means, dictionary is organized in such a way that, your lookup is fast.
Even hash tables are designed so that your lookup is fast. But you should know the key to look for. For example, Take a normal array. You know that you need to get the 5th element from it. then, you simply do array[5]. This means, your lookup is just O(1).
Plainly, hash tables are expected to work like arrays. Just give a key, you get a value in O(1) time. But note that, in worst case, in hash tables you get O(n) as well. This happens when, your key doesn’t directly get you the value.
So, hash tables or linked list both give the same O(n) worst case. But practically hash tables need to be designed so that, the hash or the key used to access the table is unique and can identify clearly a single slot in the table.
What we are discussing till now, is direct access table. You can always find a value with the key given. If key is not unique, we may need to search a linked list. That’s it.
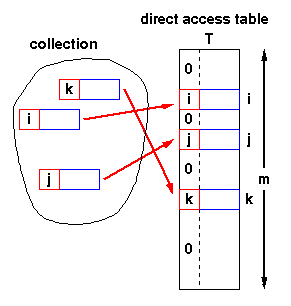
My understandings
- Just remember bucket sort. Hash tables are similar to that.
- Direct access table is impractical. But the best, if the data set to represent is small. Key’s are mostly embedded part of the table and also the data will be part of the table rather than being a list.
- If the key is not unique, it perfectly matches your bucket sort.
- Upcoming articles we will try direct access tables. Hash map has more concepts like collisions, using a cyclic buffer, rehashing etc. But without understanding direct access tables, studying those are useless.. :D
1 comment:
Stumbled across your blog today. A very impressive collection of articles. I am going through each one (wish I could get all of them in a large pdf). Keep writing :-)
Post a Comment